Geometry-Guided Camera Motion Understanding in VideoLLMs
Abstract
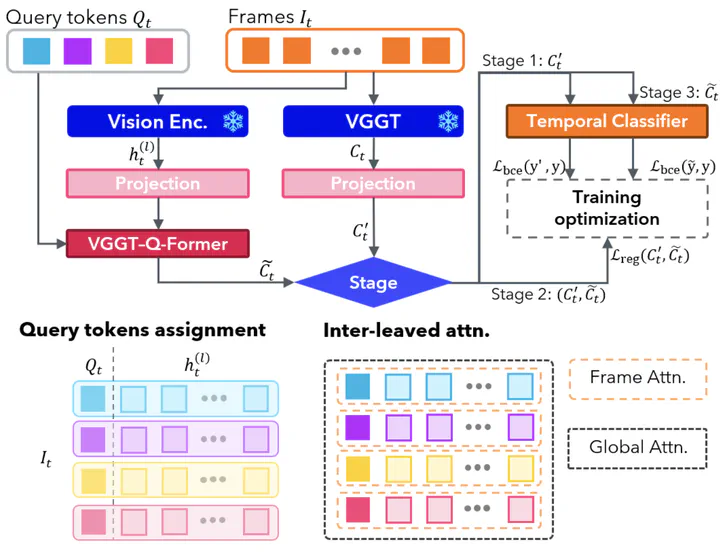
Camera motion is a fundamental geometric signal that shapes visual perception and cinematic style, yet current video-capable vision-language models (VideoLLMs) rarely represent it explicitly and often fail on fine-grained motion primitives. We address this gap with a framework of benchmarking, diagnosis, and injection. We curate CameraMotionDataset, a large-scale synthetic dataset with explicit camera control, formulate camera motion as constraint-aware multi-label recognition, and construct a VQA benchmark, CameraMotionVQA. Across diverse off-the-shelf VideoLLMs, we observe substantial errors in recognizing camera motion primitives. Probing experiments on a Qwen2.5-VL vision encoder suggest that camera motion cues are weakly represented, especially in deeper ViT blocks, helping explain the observed failure modes. To bridge this gap without costly training or fine-tuning, we propose a lightweight, model-agnostic pipeline that extracts geometric camera cues from 3D foundation models (3DFMs), predicts constrained motion primitives with a temporal classifier, and injects them into downstream VideoLLM inference via structured prompting. Experiments demonstrate improved motion recognition and more camera-aware model responses, highlighting geometry-driven cue extraction and structured prompting as practical steps toward a camera-aware VideoLLM and VLA system. The dataset and benchmark is publicly available at here.
Type
Publication
In CVPR 2026 Workshop on Pixel-level Video Understanding in the Wild (PVUW)
Accepted at CVPR 2026 Workshop PVUW. This work studies how to make VideoLLMs more camera-aware by benchmarking camera motion understanding and injecting geometry-derived motion cues at inference time.