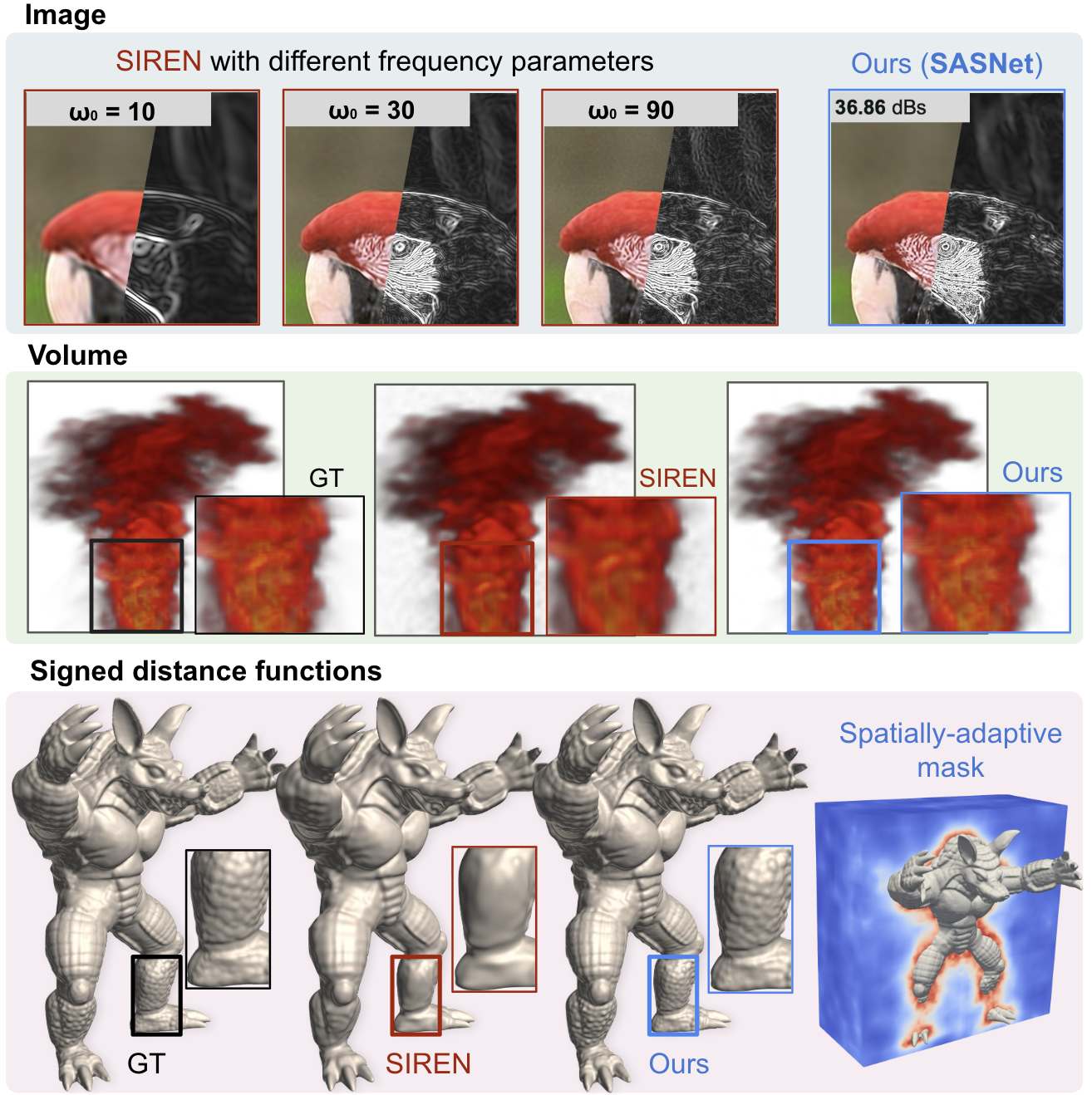
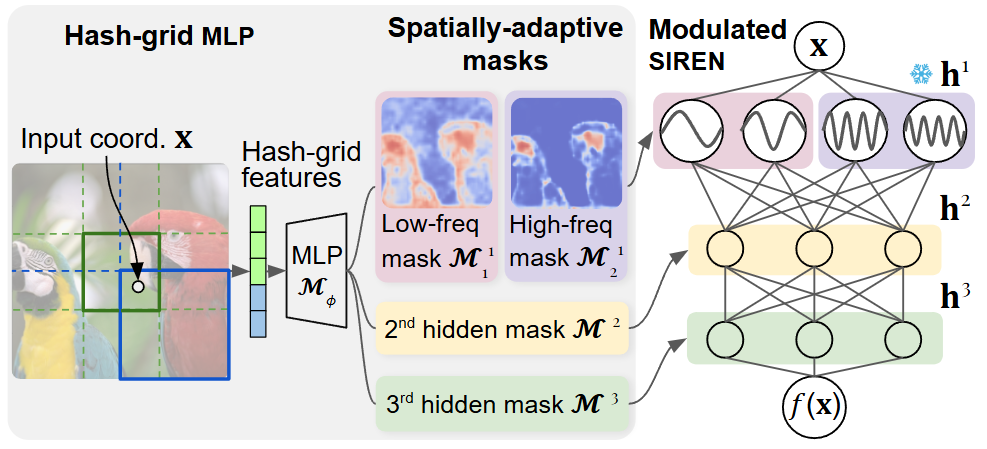
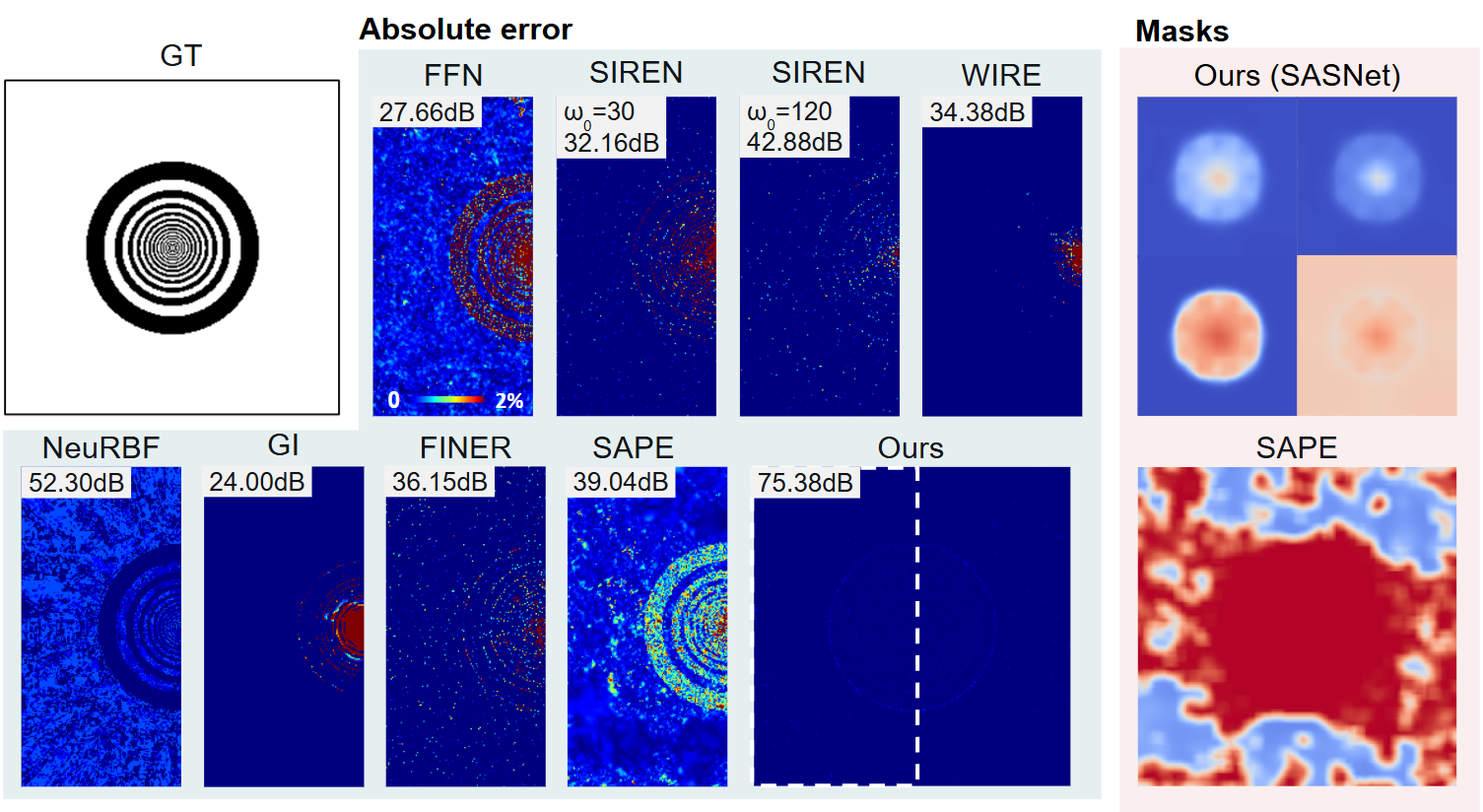
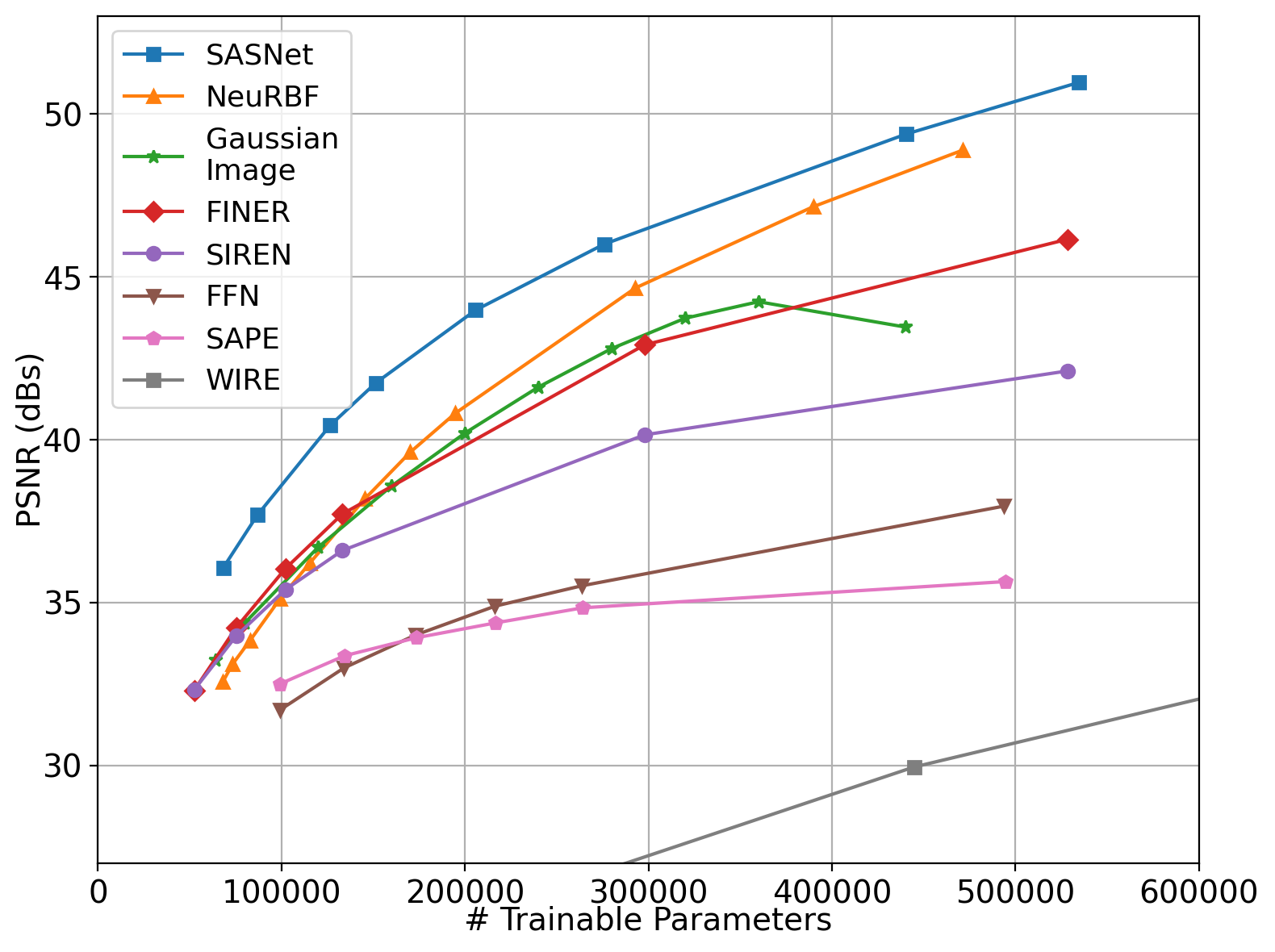
Method
SASNet architecture
A frozen frequency embedding layer fixes the spectral support of the network,
following Novello et al. (2024). In parallel, a multi-scale hash-grid MLP
predicts per-layer spatial masks $\mathcal{M}^i(\mathbf{x}) \in [0,1]^{n_i}$, which modulate the
sinusoidal neuron activations through an element-wise (Hadamard) product. The mask generation network
and the SIREN backbone are trained jointly.
① Frequency embedding layer
Each sinusoidal neuron in the $i$-th layer of a SIREN can be written as
$h_j^{i}(\mathbf{x}) = \sin\!\Bigg(\sum_{k=1}^{n} W_{jk}^{i}\,\underbrace{\sin(\mathbf{y}_k^{i-1})}_{h_k^{i-1}(\mathbf{x})} + b_j^{i}\Bigg)$,
where $\mathbf{y}^{i-1}$ denotes $\mathbf{h}^{i-1}(\mathbf{x})$ before activation and $W^{i}_{jk}$ controls
how strongly neuron $h_k^{i-1}$ contributes to the next layer. Novello et al. (2024) show that this
neuron admits the expansion
$h_j^{i}(\mathbf{x}) \;=\; \sum_{\mathbf{k}\in\mathbb{Z}^{n_i}} \alpha_{\mathbf{k}} \sin\!\Big(\langle \mathbf{k},\mathbf{y}\rangle + b_j^{i}\Big), \qquad \alpha_{\mathbf{k}} = \prod_{l} J_{k_l}(W_{jl}^{i})$,
where $J_{k_l}$ denotes the Bessel function of the first kind. The amplitudes $\alpha_{\mathbf{k}}$ depend only
on the network weights, and the generated frequencies are integer linear combinations
$\langle \mathbf{k}, \omega \rangle$ of the input frequencies $\omega$. Consequently, the input frequencies
fully determine the spectrum of the entire network.
SASNet exploits this property by initializing $\omega$ to cover a broad spectral range, sampling most components
from a low-frequency band $[-\mathcal{L}, \mathcal{L}]^{n_0}$ and the remainder from a higher band, and then
freezing $\omega$ during training. Only the amplitudes $\alpha_{\mathbf{k}}$ are learned. This
keeps the spectrum stable throughout optimization, in contrast to standard SIRENs whose effective frequencies
drift, and accelerates convergence.
② Spatially-adaptive masks
The amplitudes $\alpha_{\mathbf{k}}$ above are independent of the spatial coordinate $\mathbf{x}$, so each
high-frequency component contributes globally across the domain, including in smooth regions. To localize
these contributions, SASNet multiplies each neuron by a learned mask
$\mathcal{M}_j^{i}(\mathbf{x}) \in [0,1]$, yielding the spatially modulated neuron
$\widetilde{h_j^{i}}(\mathbf{x}) \;=\; \mathcal{M}_j^{i}(\mathbf{x})\, h_j^{i}(\mathbf{x}) \;=\;
\sum_{\mathbf{k}\in\mathbb{Z}^{n_i}} \alpha_{\mathbf{k}}\, \mathcal{M}_j^{i}(\mathbf{x})\,
\sin\!\Big(\langle \mathbf{k},\mathbf{y}\rangle + b_j^{i}\Big)$.
The product $\alpha_{\mathbf{k}}\,\mathcal{M}_j^{i}(\mathbf{x})$ now plays the role of a
spatially dependent amplitude: a frequency component contributes only where the corresponding mask is
nonzero. Applied to the frequency embedding layer, $\mathcal{M}^1(\mathbf{x}) \odot \sin(\omega\mathbf{x} + \varphi)$
directly selects which input frequencies are visible in each region.
The masks $\mathcal{M}_\phi$ are parameterized by a small multi-scale hash-grid network (Müller et al., 2022)
and trained jointly with the SIREN parameters. To control parameter count, neurons in each layer are partitioned
into groups and a single mask is broadcast across all neurons within a group. In the frequency embedding layer,
neurons are grouped by the magnitude of their initialized frequency; in hidden layers, neurons are partitioned
evenly.